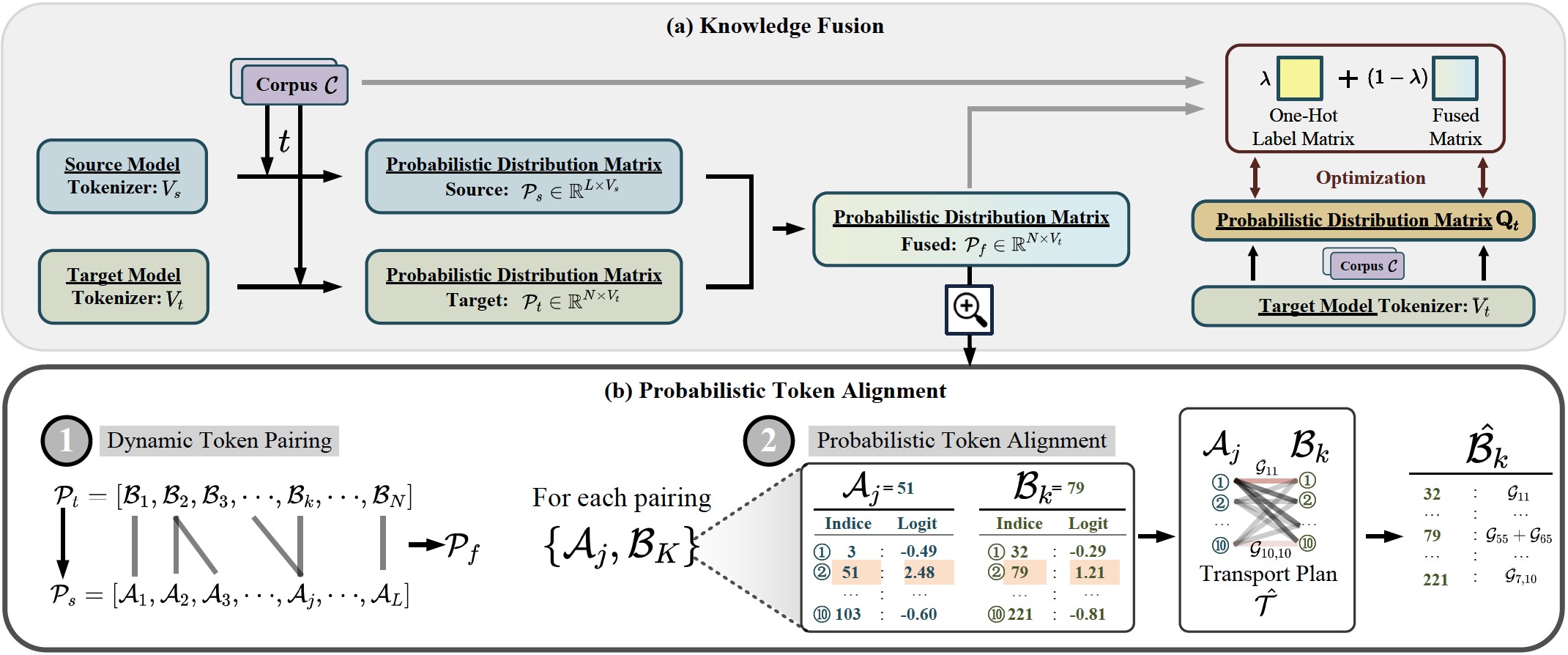
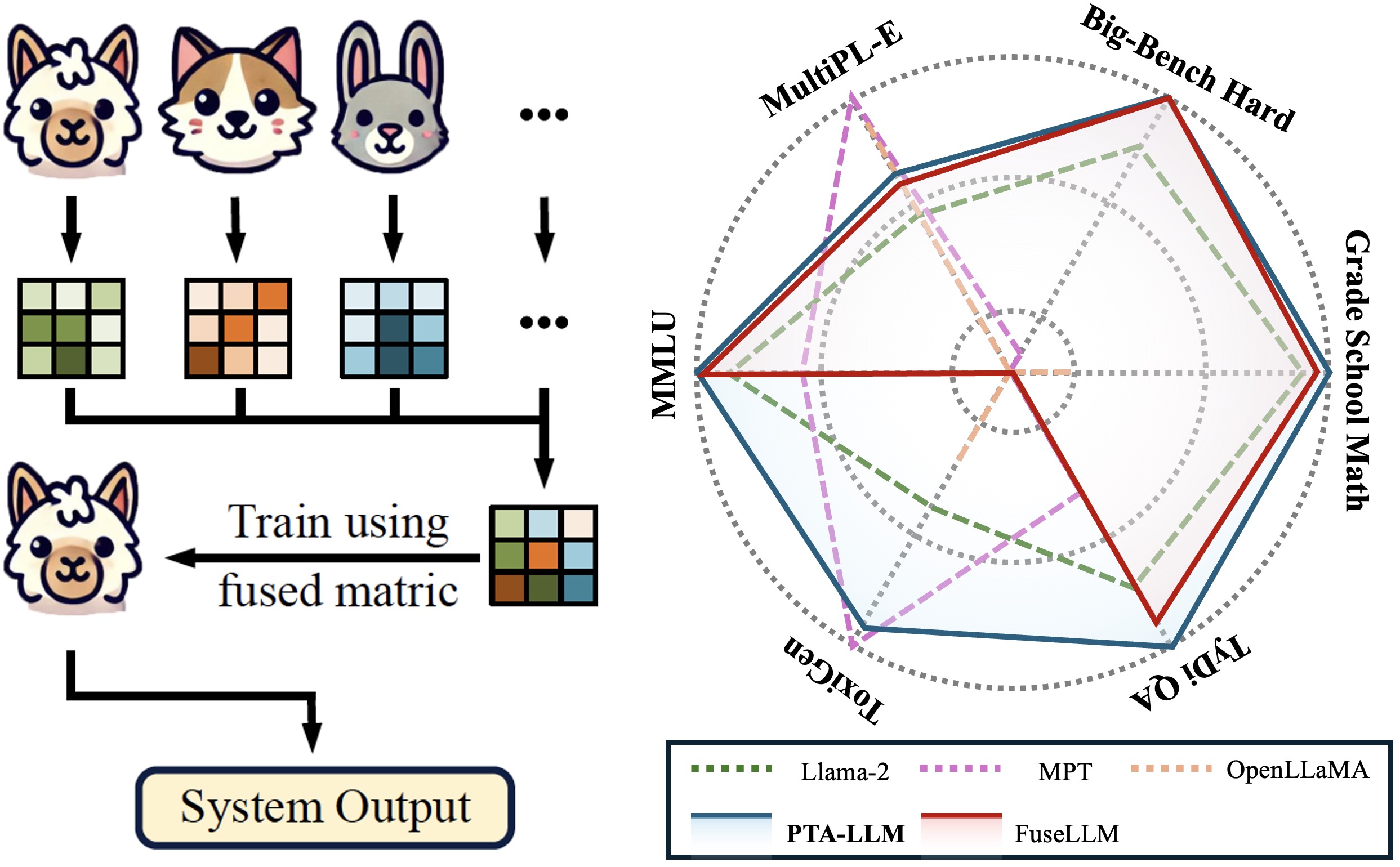
Training large language models (LLMs) from scratch can yield models with unique functionalities and strengths, but it is costly and often leads to redundant capabilities. A more cost-effective alternative is to fuse existing pre-trained LLMs with different architectures into a more powerful model. However, a key challenge in existing model fusion is their dependence on manually predefined vocabulary alignment, which may not generalize well across diverse contexts, leading to performance degradation in several evaluation.
To solve this, we draw inspiration from distribution learning and propose the probabilistic token alignment method as a general and soft mapping for alignment, named as PTA-LLM. Our approach innovatively reformulates token alignment into a classic mathematical problem: optimal transport, seamlessly leveraging distribution-aware learning to facilitate more coherent model fusion. Apart from its inherent generality, PTA-LLM exhibits interpretability from a distributional perspective, offering insights into the essence of the token alignment. Empirical results demonstrate that probabilistic token alignment enhances the target model's performance across multiple capabilities.
P.S. The video and slides are on the way!!

@inproceedings{zeng2025probabilistic,
title={Probabilistic Token Alignment for Large Language Model Fusion},
author={Zeng, Runjia and Liang, James Chenhao and Han, Cheng and Cao, Zhiwen and Liu, Jiahao and Quan, Xiaojun and Chen, Yingjie Victor and Huang, Lifu and Geng, Tong and Wang, Qifan and Liu, Dongfang},
booktitle={NeurIPS},
year={2025}
}