2026
Q-Bridge: Code Translation for Quantum Machine Learning via LLMs
Runjia Zeng, Priyabrata Senapati, Ruixiang Tang, Dongfang Liu, Qiang Guan
arXiv 2026
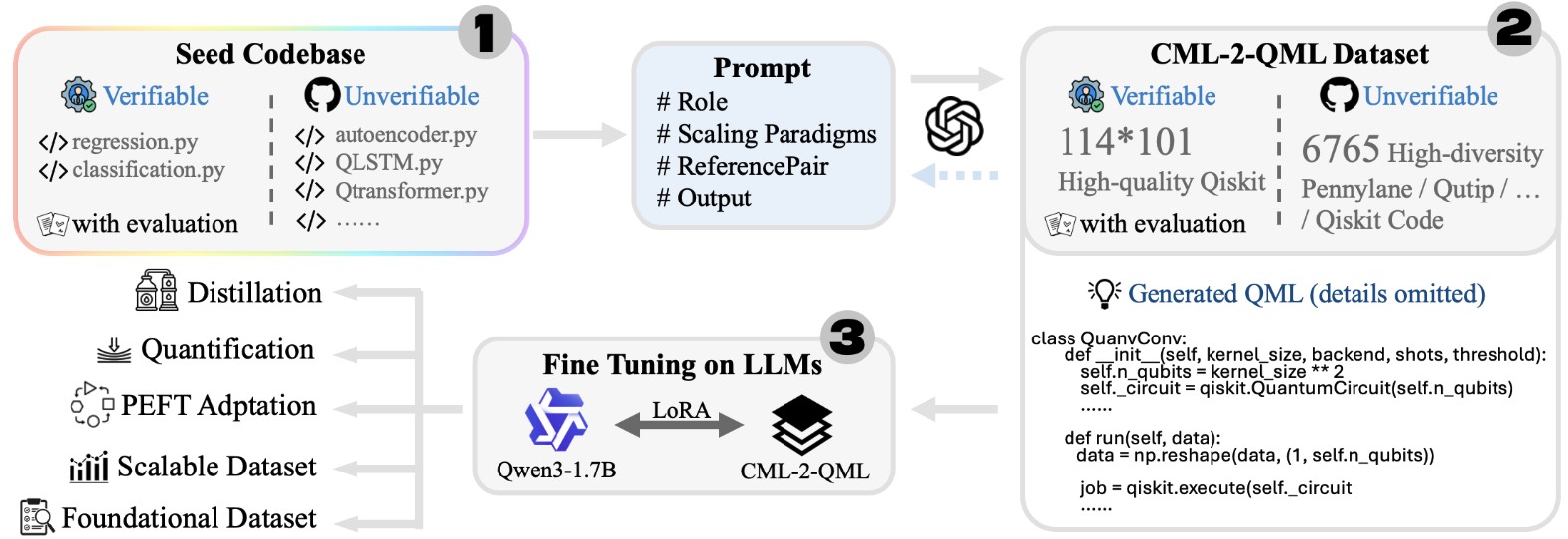
Q-Bridge is an LLM-guided framework for translating classical machine learning code into executable quantum machine learning variants, addressing the lack of standardized datasets and robust translation pipelines in this space. It builds a large-scale CML-2-QML dataset through a self-involving expansion process and fine-tunes the Q-Bridge model with supervised LoRA for scalable, memory-efficient training. Experiments and case studies show faithful, interpretable quantum code generation, supporting both deterministic correctness and creative architectural exploration.
Q-Bridge: Code Translation for Quantum Machine Learning via LLMs
Runjia Zeng, Priyabrata Senapati, Ruixiang Tang, Dongfang Liu, Qiang Guan
arXiv 2026
Q-Bridge is an LLM-guided framework for translating classical machine learning code into executable quantum machine learning variants, addressing the lack of standardized datasets and robust translation pipelines in this space. It builds a large-scale CML-2-QML dataset through a self-involving expansion process and fine-tunes the Q-Bridge model with supervised LoRA for scalable, memory-efficient training. Experiments and case studies show faithful, interpretable quantum code generation, supporting both deterministic correctness and creative architectural exploration.
TokenSeek: Memory Efficient Fine Tuning via Instance-Aware Token Ditching
Runjia Zeng, Qifan Wang, Qiang Guan, Ruixiang Tang, Lifu Huang, Zhenting Wang, Xueling Zhang, Cheng Han, Dongfang Liu
ICLR International Conference on Learning Representations 2026
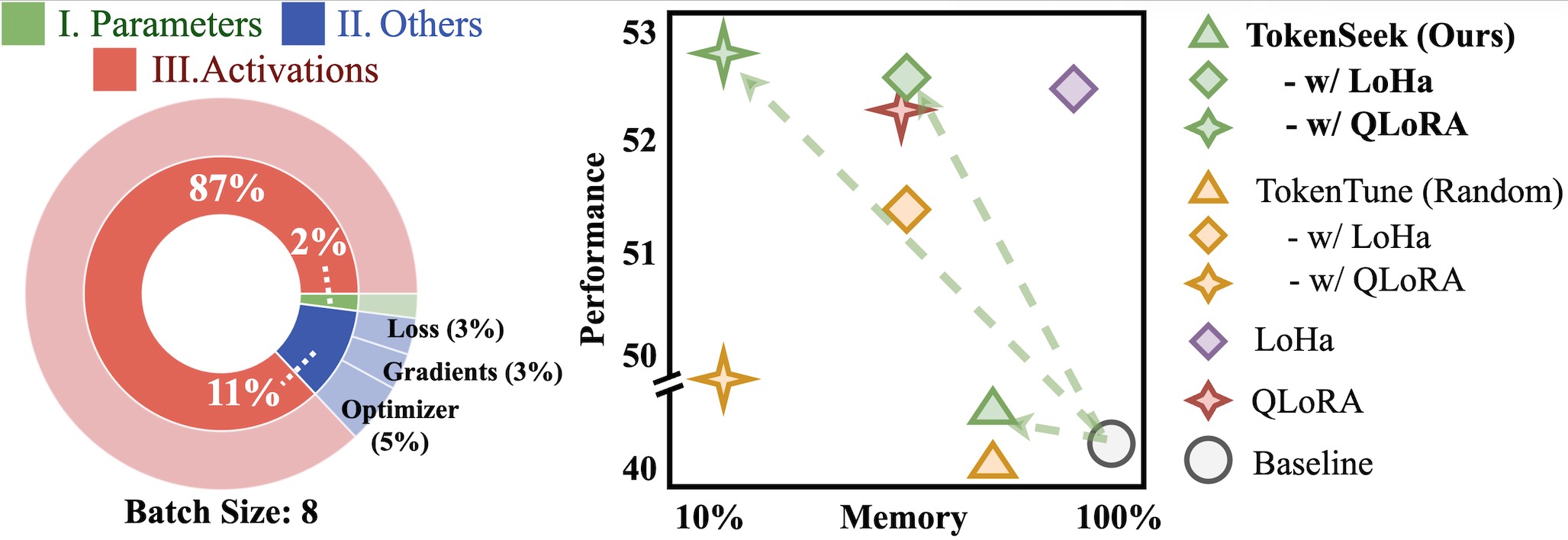
Fine-tuning is a standard approach for adapting large language models to downstream tasks, but its efficiency is limited by high memory consumption, largely dominated by activations. We propose TokenSeek, a universal plugin for transformer-based models that performs instance-aware token seeking and ditching, achieving substantial memory savings (e.g., only 14.8% on Llama3.2 1B) while maintaining or even improving performance. Moreover, its interpretable token-seeking mechanism provides insights into why token efficiency can be improved.
TokenSeek: Memory Efficient Fine Tuning via Instance-Aware Token Ditching
Runjia Zeng, Qifan Wang, Qiang Guan, Ruixiang Tang, Lifu Huang, Zhenting Wang, Xueling Zhang, Cheng Han, Dongfang Liu
ICLR International Conference on Learning Representations 2026
Fine-tuning is a standard approach for adapting large language models to downstream tasks, but its efficiency is limited by high memory consumption, largely dominated by activations. We propose TokenSeek, a universal plugin for transformer-based models that performs instance-aware token seeking and ditching, achieving substantial memory savings (e.g., only 14.8% on Llama3.2 1B) while maintaining or even improving performance. Moreover, its interpretable token-seeking mechanism provides insights into why token efficiency can be improved.
2025
Probabilistic Token Alignment for Large Language Model Fusion
Runjia Zeng, James Chenhao Liang, Cheng Han, Zhiwen Cao, Jiahao Liu, Xiaojun Quan, Yingjie Victor Chen, Lifu Huang, Tong Geng, Qifan Wang, Dongfang Liu
NeurIPS Conference on Neural Information Processing Systems 2025
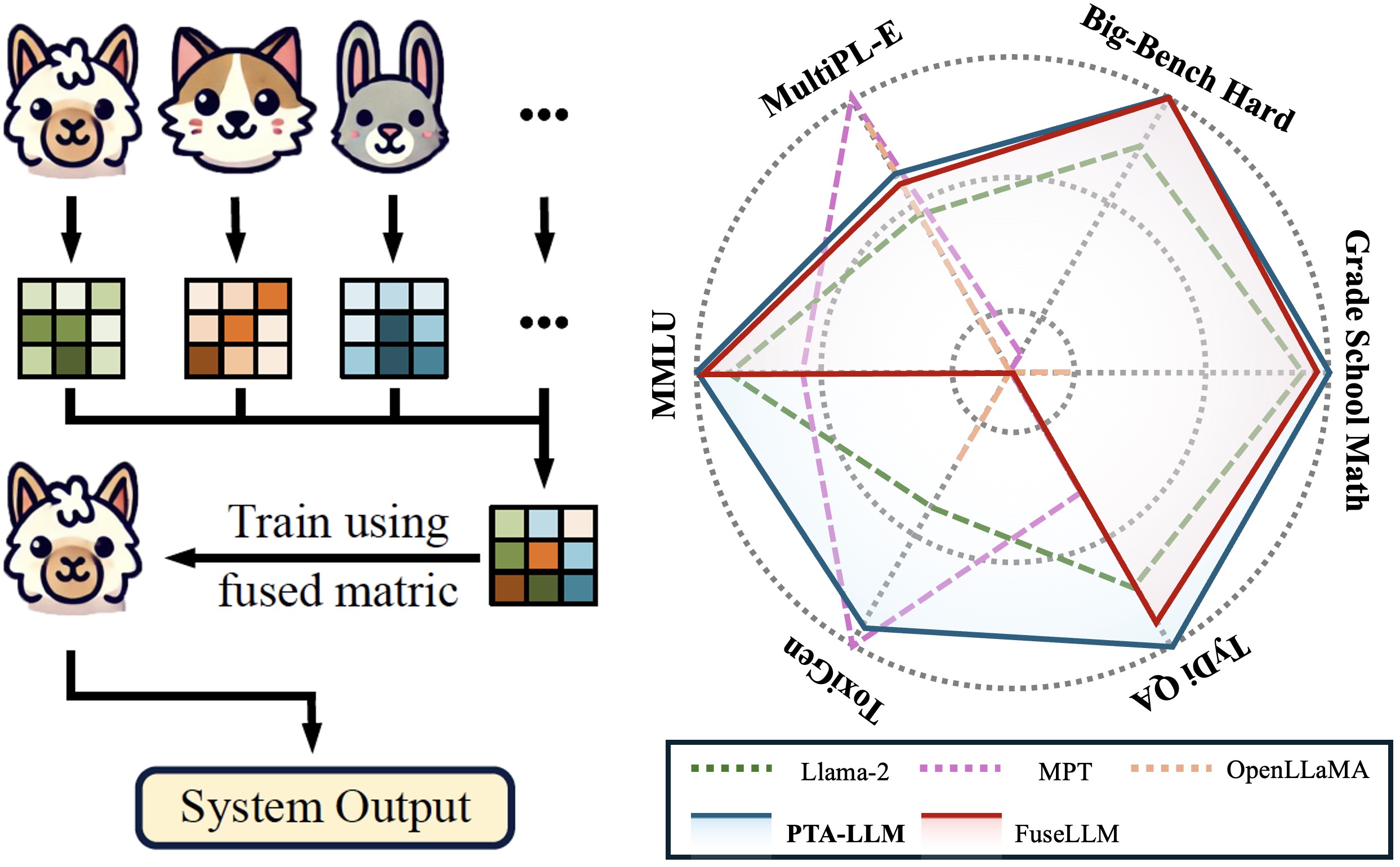
We introduce Probabilistic Token Alignment (PTA) for large language model fusion, reformulating token alignment as an optimal transport problem. PTA enhances performance and generality through distribution-aware learning while offering interpretability from a distributional perspective, which provides deeper insights into token alignment.
Probabilistic Token Alignment for Large Language Model Fusion
Runjia Zeng, James Chenhao Liang, Cheng Han, Zhiwen Cao, Jiahao Liu, Xiaojun Quan, Yingjie Victor Chen, Lifu Huang, Tong Geng, Qifan Wang, Dongfang Liu
NeurIPS Conference on Neural Information Processing Systems 2025
We introduce Probabilistic Token Alignment (PTA) for large language model fusion, reformulating token alignment as an optimal transport problem. PTA enhances performance and generality through distribution-aware learning while offering interpretability from a distributional perspective, which provides deeper insights into token alignment.
MEPT: Mixture of Experts Prompt Tuning as a Manifold Mapper
Runjia Zeng, Guangyan Sun, Qifan Wang, Tong Geng, Sohail Dianat, Xiaotian Han, Raghuveer Rao, Xueling Zhang, Cheng Han, Lifu Huang, Dongfang Liu
EMNLP Conference on Empirical Methods in Natural Language Processing 2025
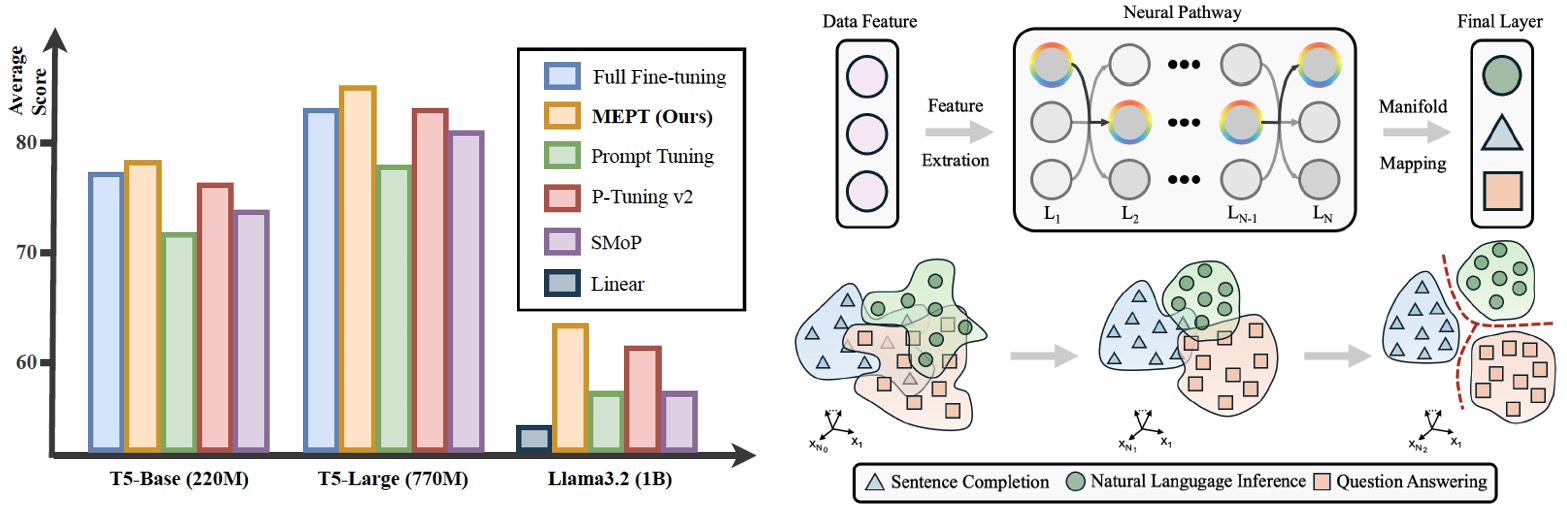
Considering deep neural networks as manifold mappers, the pretrain-then-fine-tune paradigm is a two-stage process: pretrain builds a broad knowledge base, and fine-tune adjusts parameters to activate specific neural pathways aligning with the target manifold. The rigid parameter space constrain of prior prompt tuning methods limits dynamic pathway activation, making them less adaptable to diverse and evolving data. In this view, we propose Mixture of Expert Prompt Tuning (MEPT) that leverages multiple prompt experts to adaptively learn diverse and non-stationary data distributions.
MEPT: Mixture of Experts Prompt Tuning as a Manifold Mapper
Runjia Zeng, Guangyan Sun, Qifan Wang, Tong Geng, Sohail Dianat, Xiaotian Han, Raghuveer Rao, Xueling Zhang, Cheng Han, Lifu Huang, Dongfang Liu
EMNLP Conference on Empirical Methods in Natural Language Processing 2025
Considering deep neural networks as manifold mappers, the pretrain-then-fine-tune paradigm is a two-stage process: pretrain builds a broad knowledge base, and fine-tune adjusts parameters to activate specific neural pathways aligning with the target manifold. The rigid parameter space constrain of prior prompt tuning methods limits dynamic pathway activation, making them less adaptable to diverse and evolving data. In this view, we propose Mixture of Expert Prompt Tuning (MEPT) that leverages multiple prompt experts to adaptively learn diverse and non-stationary data distributions.
2024
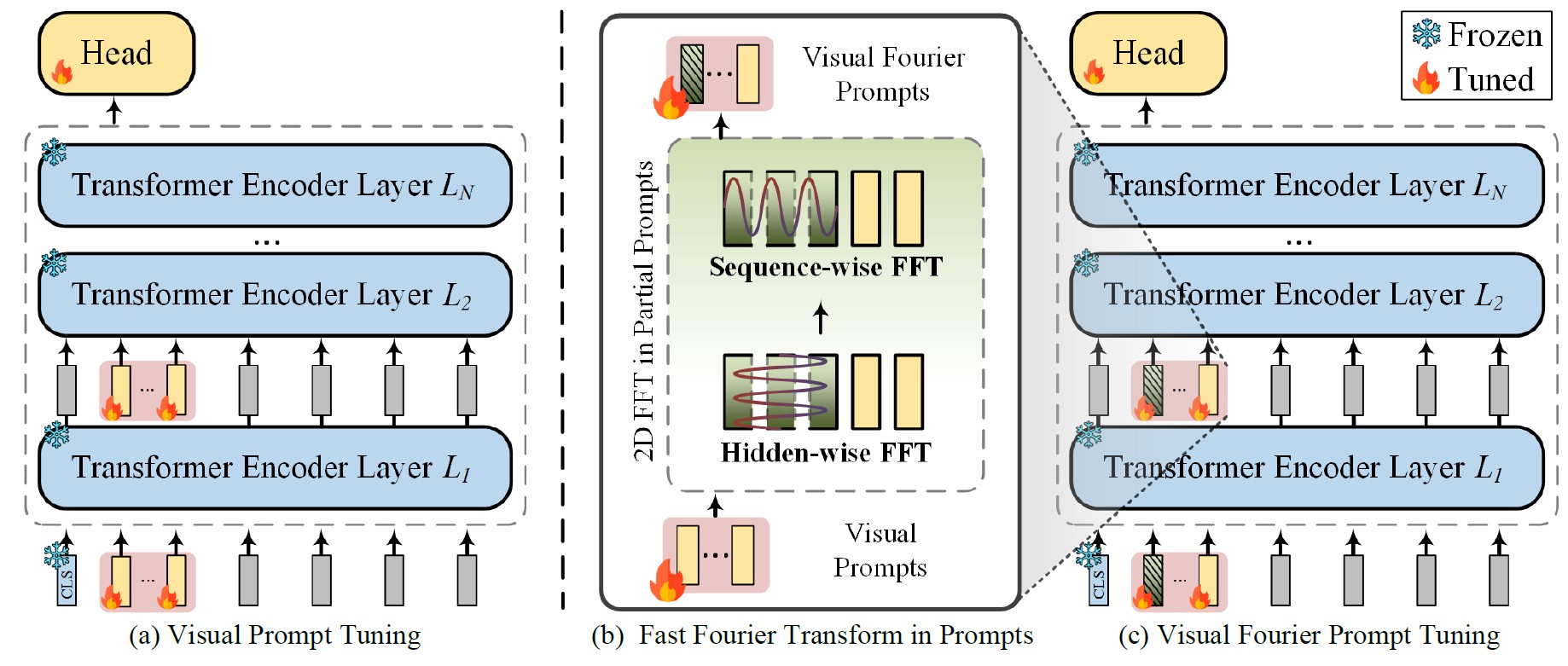
Visual Fourier Prompt Tuning

Runjia Zeng, Cheng Han, Qifan Wang, Chunshu Wu, Tong Geng, Lifu Huang, Ying Nian Wu, Dongfang Liu
NeurIPS Conference on Neural Information Processing Systems 2024
To tackle performance drops caused by data differences between pretraining and finetuning, we propose Visual Fourier Prompt Tuning (VFPT), which leverages the Fast Fourier Transform to combine spatial and frequency domain information, achieving better results with fewer parameters.
[Homepage💻] [Code💾] [Paper📑] [Slide📂] [Video🎞️] [Poster🎇] [Media Coverage🎙️]
Visual Fourier Prompt Tuning
Runjia Zeng, Cheng Han, Qifan Wang, Chunshu Wu, Tong Geng, Lifu Huang, Ying Nian Wu, Dongfang Liu
NeurIPS Conference on Neural Information Processing Systems 2024
To tackle performance drops caused by data differences between pretraining and finetuning, we propose Visual Fourier Prompt Tuning (VFPT), which leverages the Fast Fourier Transform to combine spatial and frequency domain information, achieving better results with fewer parameters.
[Homepage💻] [Code💾] [Paper📑] [Slide📂] [Video🎞️] [Poster🎇] [Media Coverage🎙️]
